junelee (june lee) (huggingface.co) 님이 작성하신 Vicuna 7B 를 양자화 해보기로 했다. 마침 convert.py가 huggingface format이 아니어도 변환이 가능하게 바뀌었다고 해서 도전하기로 함.
Llama.cpp 설치
ggerganov/llama.cpp: Port of Facebook's LLaMA model in C/C++ (github.com) 에 나와있는 설치 순서를 따른다. (Miniconda 설치 및 가상환경 설정은 완료됐다고 가정.)
git clone <https://github.com/ggerganov/llama.cpp>
cd llama.cpp
make
cd models
models 폴더 안에 tokenizer_checklist.chk tokenizer.model 두개를 넣는다.
nyanko7/LLaMA-7B · Hugging Face 여기에서 두개 파일을 얻을 수 있다.
그리고 models 폴더에 KoVicuna를 gitclone 한다.
git clone <https://huggingface.co/junelee/ko_vicuna_7b>
clone이 완료되고나면, llama.cpp 폴더로 가서 requirements 를 설치해준다.
cd ..
python3 -m pip install -r requirements.txt
python3 convert.py models/ko_vicuna_7b/
ggml-model-f32.bin 파일이 생성된 것을 ko_vicuna_7b 폴더에서 확인 할 수 있는데, 이것을 양자화 한다.
./quantize ./models/ko_vicuna_7b/ggml-model-f32.bin ./models/ko_vicuna_7b/ggml-model-q4_0bin 2
./main -m ./models/ko_vicuna_7b/ggml-model-q4_0bin -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
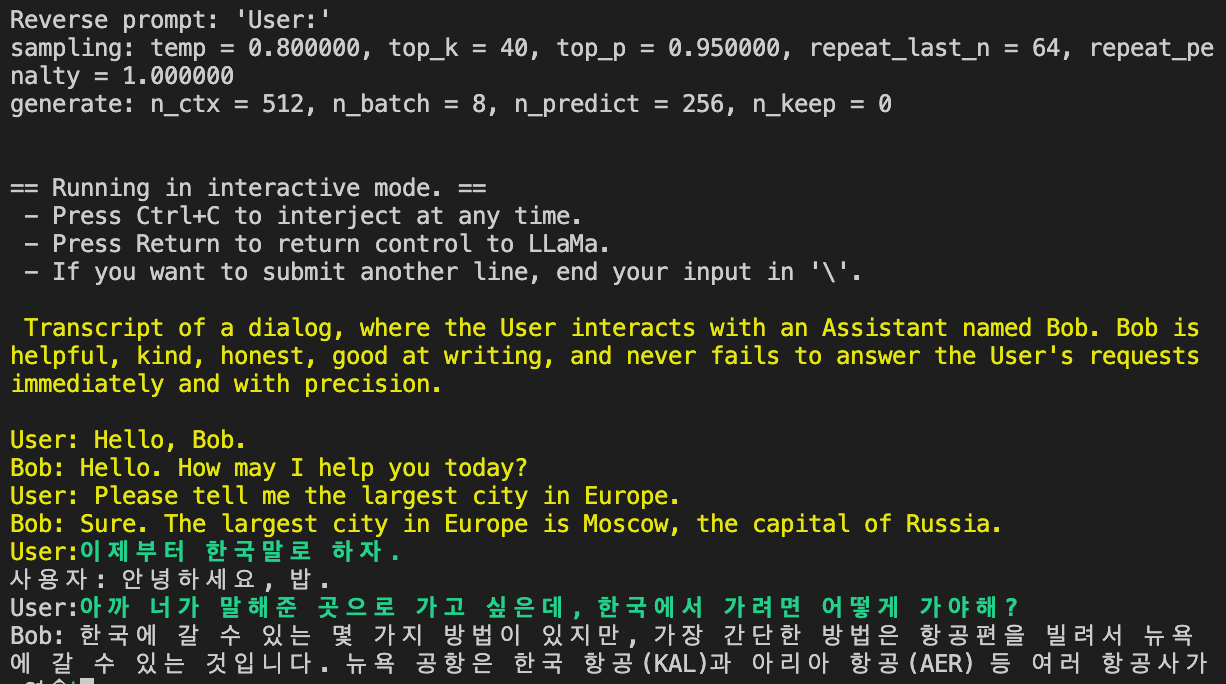
답변이 만족스럽지 않고 속도도 느렸지만, 그래도 된다!
I decided to quantize the Vicuna 7B written by junelee (june lee) (huggingface.co) . Even if convert.py is not a huggingface format, it has been changed to enable conversion, so I decided to challenge it.
Install Llama.cpp
Follow the installation instructions at ggerganov/llama.cpp: Port of Facebook's LLaMA model in C/C++ (github.com) . (Assuming that Miniconda installation and virtual environment settings are completed.)
git clone <https://github.com/ggerganov/llama.cpp>
cd llama.cpp
make
cd models
Put two tokenizer_checklist.chk tokenizer.model in the models folder.
nyanko7/LLaMA-7B · Hugging Face You can get two files here.
And gitclone KoVicuna in the models folder.
git clone <https://huggingface.co/junelee/ko_vicuna_7b>
After clone is complete, go to llama.cpp folder and install requirements.
cd ..
python3 -m pip install -r requirements.txt
python3 convert.py models/ko_vicuna_7b/
You can check that ggml-model-f32.bin file was created in the ko_vicuna_7b folder, and quantize it.
./quantize ./models/en_vicuna_7b/ggml-model-f32.bin ./models/ko_vicuna_7b/ggml-model-q4_0bin 2
./main -m ./models/ko_vicuna_7b/ggml-model-q4_0bin -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
The answer wasn't satisfactory and the speed was slow, but that's okay!